|
п»ҝ
|
| мҳӨлқјнҒҙ мӢӨмҠө |
|
[1] |
 |
л“ұлЎқмқј:2009-05-28 00:54:27  (0%) (0%)
мһ‘м„ұмһҗ:
м ңлӘ©:л°°м№ҳ(BATCH)нҳ• к°ңл°ң |
|
лӢӨ. л°°м№ҳнҳ• к°ңл°ң
- к°ҖмһҘ нқ”н•ң нҳ•нғңк°Җ INSERTлҘј н•ҙм•ј н• м§Җ UPDATEлҘј н•ҙм•ј н• м§Җ нҢҗлӢЁмқҙ м„ңм§Җ м•Ҡмқ„ л•Ң UPDATEлҘј лЁјм Җ мӢңлҸ„н•ң нӣ„ мӢӨнҢЁн•ҳл©ҙ INSERTлҘј мӢңлҸ„н•ңлӢӨ.
- мөңм•…мқҳ кІҪмҡ° SQLмқ„ н•ӯмғҒ 2лІҲ мҲҳн–үмӢңмјңм•ј н•ҳлҠ” 비нҡЁмңЁмқҙ мһҲлӢӨ. Oracle 9i мқҙмғҒм—җм„ңлҠ” Mergeл¬ёмқ„ мқҙмҡ©н•ҳм—¬ н•ңлІҲм—җ мҲҳн–үн• мҲҳ мһҲлӢӨ.
- Merge문
MARGE INTO target_name
USING (table|view|subquery) ON (join condition)
WHEN MATCHED THEN
UPDATE SET col1 = val1[,col2=val2]
WHEN NOT MATCHED THEN
INSER(....) VALUES(....)
- INTO : DATAк°Җ UPDATE лҗҳкұ°лӮҳ INSERTлҗ TABLE мқҙлҰ„мқ„ м§Җм •н•©лӢҲлӢӨ.
- USING : лҢҖмғҒ TABLEмқҳ DATAмҷҖ 비көҗн•ң нӣ„ UPDATE лҳҗлҠ” INSERTн• лҢҖмғҒмқҙ лҗҳлҠ” DATAмқҳ SOURCE н…Ңмқҙлё” лҳҗлҠ” л·°лҘј м§Җм •
- ON : UPDATEлӮҳ INSERTлҘј н•ҳкІҢ лҗ мЎ°кұҙмңјлЎң, н•ҙлӢ№ conditionмқ„ л§ҢмЎұн•ҳлҠ” DATAк°Җ мһҲмңјл©ҙ WHEN MATCHEDм Ҳмқ„ мӢңн–үн•ҳкІҢ лҗҳкі м—Ҷмңјл©ҙ WHEN NOT MATCHED мқ„ мӢӨн–үн•ҳкІҢ лҗ©лӢҲлӢӨ.
- WHEN MATCHED : ON мЎ°кұҙм Ҳмқҙ TRUEмқё ROWм—җ мҲҳн–үн• лӮҙмҡ©
- WHEN NOT MATCHED : ON мЎ°кұҙм Ҳм—җ л§һлҠ” ROWк°Җ м—Ҷмқ„ л•Ң мҲҳн–үн• лӮҙмҡ©.
- INSERTк°Җ л§ҺмқҖ кІҪмҡ°мқҳ л°°м№ҳмІҳлҰ¬
 |
- UPDATE н• л ҲмҪ”л“ңл§Ң 추м¶ңн•ҳм—¬ мһ„мӢң TABLEм—җ ліҙкҙҖ
- ARRAY PROCESSINGмңјлЎң INSERT
- мһ„мӢң TABLEкіј мІҳлҰ¬ TABLEмқ„ JOIN
- ARRAY PROCESSINGмңјлЎң UPDATE мІҳлҰ¬(ROWID)
- мһ„мӢң TABLE DROP
|
- SQLмқ„ мқҙмҡ©н•ң л°°м№ҳмІҳлҰ¬
|
- н•ҳлӮҳмқҳ SQLлЎң мІҳлҰ¬лҗҳкё° л•Ңл¬ём—җ м „мІҙ мһ‘м—…мқҙ мҷ„лЈҢлҗҳм—Ҳмқ„ л•Ңл§Ң м»Өл°ӢмқҙлӮҳ лЎӨл°ұмқ„ н• мҲҳ мһҲлӢӨ. к·ёлҹ¬лҜҖлЎң л„Ҳл¬ҙ л§ҺмқҖ лЎңмҡ°лҘј мІҳлҰ¬н• л•ҢлҠ” мӮ¬мҡ©н•ҳм§Җ м•ҠлҠ” кІғмқҙ мўӢлӢӨ.
: sub queryм Ҳм—җ н•ҙлӢ№н•ҳлҠ” Temp Tableмқ„ л§Ңл“Өм–ҙ лӢӨмӨ‘ мІҳлҰ¬лҘј кі л Өн•ңлӢӨ.
- м„ңлёҢмҝјлҰ¬ мЎ°кұҙмқ„ л§ҢмЎұн•ҳлҠ” лЎңмҡ°к°Җ н•ҳлӮҳлҸ„ м—Ҷм–ҙ 'No Data Found'к°Җ лҗҳм—Ҳмқ„ л•ҢлҠ” SET м Ҳм—җ кё°мҲ н•ң UPDATE 컬лҹјл“Өм—җ NULLк°’мқҙ UPDATE лҗңлӢӨ.
- NVL()
- EXSITS
- Updatable Join View
- м°ёкі ) 집계 н•ЁмҲҳлҠ” ReturnлҗҳлҠ” н–үмқҙ м—ҶлҚ”лқјлҸ„ NULL к°’мңјлЎң RowлҘј л°ҳнҷҳн•ңлӢӨ. лӢЁ COUNT()лҠ” мҳҲмҷё
|
JDBC л°°м№ҳмӢӨн–ү
- JDBC н”„лЎңк·ёлһҳл°Қмқ„ к°ңм„ н•ҳлҠ” мӣҗм№ҷмқҖ лӢӨмқҢ л‘җк°Җм§ҖлЎң мҡ”м•Ҫн• мҲҳ мһҲлӢӨ.
- к°ҖлҠҘн•ң лҚң мҲҳн–үн•ҳлқј
- к°ҖлҠҘн•ң н•ңкәјлІҲм—җ мҲҳн–үн•ҳлқј
- к°ҖлҠҘн•ң лҚң мҲҳн–үн•ҳлқј
: м»Өм„ңлҘј мһ¬нҷңмҡ©н•ҳлқј. мқҙкІғмқҖ мқјлӢЁ мғқм„ұ(мҳӨн”Ҳ)н•ң м»ӨмҠӨлҘј лӢ«м§Җ м•Ҡкі мөңлҢҖн•ң м—¬лҹ¬лІҲ нҷңмҡ©н•ңлӢӨлҠ” мқҳлҜёмқҙлӢӨ.
Case1: StatementлҘј мһ¬нҷңмҡ©н•ҳм§Җ м•ҠлҠ” кІҪмҡ°
startTime = System.currentTimeMillis();
for(int idx=1;idx<=10000; idx++){
pstmt = conn.prepareStatement("SELECT /* NO REUSER */ 1 FROM java_test WHERE ROWNUM = ?");
pstmt.setInt(1,1);
ResultSet rs = pstmt.executeQuery();
pstmt.close(); }
endTime = System.currentTimeMillis();
System.out.println("Case1: "+ (endTime - startTime )/10 + " (cs) elapsed");
Case2: StatementлҘј мһ¬нҷңмҡ©н•ҳлҠ” кІҪмҡ°
startTime = System.currentTimeMillis();
for(int idx=1;idx<=10000; idx++){
pstmt = conn.prepareStatement("SELECT /* NO REUSER */ 1 FROM java_test WHERE ROWNUM = ?");
pstmt.setInt(1,1);
ResultSet rs = pstmt.executeQuery();
}
pstmt.close();
endTime = System.currentTimeMillis();
System.out.println("Case2: "+ (endTime - startTime )/10 + " (cs) elapsed");
Case1: 7136 (cs) elapsed
Case2: 1015 (cs) elapsed
- к°ҖлҠҘн•ң н•ңкәјлІҲм—җ мҲҳн–үн•ҳлқј
: JDBCм—җм„ңлҠ” pREPAREDsTATEMENT к°қмІҙмқҳ addBatch, executeBatch л©”мҶҢл“ңлҘј мқҙмҡ©н•ҙм„ң л°°м№ҳ мӢӨн–үмқ„ кө¬нҳ„н• мҲҳ мһҲлӢӨ.
: мЈјмқҳмӮ¬н•ӯ
- л°°м№ҳмһ‘м—… мҡ”мІӯмқ„ н•ңкәјлІҲм—җ мҲҳн–үн•ҳкё° л•Ңл¬ём—җ л¶Җк°Җм Ғмқё мһҗмӣҗ(Resource)мқ„ н•„мҡ”лЎң н•ңлӢӨ. мҰү 1000к°ңмқҳ мҡ”мІӯмқ„ н•ңлІҲм—җ л°ӣм•„м„ң мІҳлҰ¬н•ңлӢӨл©ҙ 1к°ңм”© мІҳлҰ¬н•ҳлҠ” кІҪмҡ°м—җ 비н•ҙ 1000л°°мқҳ мһҗмӣҗмқ„ мҡ”кө¬н•ңлӢӨ. л”°лқјм„ң мӢңмҠӨн…ң мһҗмӣҗнҷҳкІҪмқ„ кі л Өн•ҳм—¬ н•„мҡ”н•ң лӘЁл“Ҳмқ„ м„ лі„м ҒмңјлЎң мӮ¬мҡ©н•ҳлҸ„лЎқ н•ңлӢӨ.
Case1: Batched Executionмқ„ мӮ¬мҡ©н•ҳм§Җ м•ҠлҠ” кІҪмҡ°
startTime = System.currentTimeMillis();
pstmt = conn.prepareStatement("UPDATE/* NO BATCH*/ java_test SET id=id WHERE ROWNUM = ?");
for(int idx=1;idx<=10000; idx++){
pstmt.setInt(1,1);
pstmt.executeUpdate(); }
pstmt.close();
endTime = System.currentTimeMillis();
System.out.println("Case1: "+ (endTime - startTime )/10 + " (cs) elapsed");
Case2: Batched Executionмқ„ мӮ¬мҡ©н•ҳлҠ” кІҪмҡ°
startTime = System.currentTimeMillis();
pstmt = conn.prepareStatement("UPDATE/* NO BATCH*/ java_test SET id=id WHERE ROWNUM = ?");
for(int idx=1;idx<=10000; idx++){
pstmt.setInt(1,1);
pstmt.addBatch(); }
pstmt.executeBatch(); endTime = System.currentTimeMillis();
System.out.println("Case2: "+ (endTime - startTime )/10 + " (cs) elapsed");
Case1: 1839 (cs) elapsed
Case2: 270 (cs) elapsed
- нҺҳм№ҳнҒ¬кё°
: м»Өм„ңлҘј нҶөн•ҙ 추м¶ң(fatch)н•ҳлҠ” лҚ°мқҙн„°мқҳ м–‘мқҙ л§ҺмқҖ м–ҙн”ҢлҰ¬мјҖмқҙм…ҳмқҳ кІҪмҡ°, нҺҳм№ҳ нҒ¬кё°лҘј нҒ¬кІҢ н•ЁмңјлЎңмҚЁ мғҒлӢ№н•ң м„ұлҠҘк°ңм„ нҡЁкіјлҘј м–»мқ„ мҲҳ мһҲлӢӨ.
Case1: Fatch sizeлҘј 10мңјлЎң м„Өм •н•ң кІҪмҡ°
startTime = System.currentTimeMillis();
pstmt = conn.prepareStatement("SELECT /* SMALL FETCH SIZE */ 1 FROM java_test");
pstmt.setFatchSize(10); for(int idx=1;idx<=10000; idx++){
ResultSet rs = pstmt.executeQuery();
while(rs.next()) {} }
pstmt.close();
endTime = System.currentTimeMillis();
System.out.println("Case1: "+ (endTime - startTime )/10 + " (cs) elapsed");
Case2: Fatch sizeлҘј 100мңјлЎң м„Өм •н•ң кІҪмҡ°
startTime = System.currentTimeMillis();
pstmt = conn.prepareStatement("SELECT /* SMALL FETCH SIZE */ 1 FROM java_test");
pstmt.setFatchSize(10); for(int idx=1;idx<=10000; idx++){
ResultSet rs = pstmt.executeQuery();
while(rs.next()) {} }
pstmt.close();
endTime = System.currentTimeMillis();
System.out.println("Case2: "+ (endTime - startTime )/10 + " (cs) elapsed");
Case1: 1509 (cs) elapsed
Case2: 396 (cs) elapsed
SQL TraceкІ°кіјлҘј 비көҗн•ҙліҙл©ҙ, м„ұлҠҘ м°ЁмқҙлҘј кІ°м •м§“лҠ” мҡ”мҶҢлҠ” нҺҳм№ҳ(Fetch) нҡҹмҲҳлқјлҠ” кІғмқ„ м•Ң мҲҳ мһҲлӢӨ. нҺҳм№ҳ нҒ¬кё°к°Җ 10мқё кІҪмҡ°м—җлҠ” нҺҳм№ҳ нҡҹмҲҳк°Җ 15,000лІҲм—җ лӢ¬н•ҳлҠ” л°ҳл©ҙ, 100мқё кІҪмҡ°лҠ” 2,000м—җ л¶Ҳкіјн•ҳлӢӨ.
лҚ” мһ¬лҜёмһҲлҠ” мӮ¬мӢӨмқҖ Logical Reads(query)нҺҳм№ҳ нҒ¬кё°к°Җ мӨ„м–ҙл“ лӢӨлҠ” мӮ¬мӢӨмқҙлӢӨ!!! (к°Ғмһҗ traceл– ліҙм…Ҳ)
к·ёл Үм§Җл§Ң мқҙкІғ лҳҗн•ң л¶Җм Ғм Ҳн•ҳкІҢ мӮ¬мҡ©н•ҳл©ҙ мһҗмӣҗмқҳ кІҪн•©мқ„ мң л°ңн• мҲҳ мһҲкё° л•Ңл¬ём—җ лҢҖлҹүмқҳ 추м¶ңн•ҳлҠ” нҠ№м • лӘЁл“Ҳм—җм„ңл§Ң нҒ° нҺҳм№ҳ нҒ¬кё°лҘј м Ғмҡ©н•ҳлқј.
FATCH мҷҖ SELECT INTO м°Ёмқҙм җ
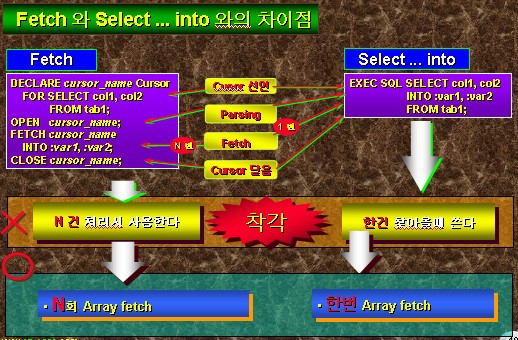
| кө¬л¶„ |
FATCH |
SELECT ... INTO |
| мҡ©лҸ„ |
Nкұҙмқҳ ARRAY FETCH |
н•ңлІҲмқҳ ARRAY FETCH |
| |
MAXк°’мқ„ лӘЁлҘјл•Ң
MAXк°Җ м§ҖлӮҳм№ҳкІҢ л„“м–ҙм„ң н•ңлІҲмқҳ FETCHлЎңлҠ” л¬ҙлҰ¬н•ң кІҪмҡ° |
MAXлҘј м•Ңл•Ң |
| мЈјмқҳм җ |
Loop Query SQL лӮҙм—җ cursorл¬ёмқ„ лӢӨмӢң declare н•ҙм„ңлҠ” м ҲлҢҖ м•ҲлҗЁ |
Loop лӮҙм—җ л°ҳліөлҗҳлҠ” nкұҙ мІҳлҰ¬ Declare SQLм—җм„ң Join н•ҳм—¬ н•ҙкІ° |
лқј. лі‘л ¬мһ‘м—…
- лі‘л ¬мҝјлҰ¬ - лӢЁмқј sqlл¬ёмқ„ м„ңлЎң лӢӨлҘё н”„лЎңм„ёмҠӨ/м“°л Ҳл“ңм—җ мқҳн•ҙ лҸҷмӢңм—җ мҲҳн–үлҗ мҲҳ мһҲлҠ” мқјл Ёмқҳ мһ‘м—…мңјлЎң л¶„н• н•ҳм—¬ мқҙл“Өмқ„ лҸҷмӢңм—җ мӢӨн–үмӢңнӮ¬ мҲҳ мһҲлҠ” лҠҘл Ҙ
- лі‘л ¬ DML(мҲҳм •) - лі‘л ¬ мҝјлҰ¬мҷҖ мң мӮ¬н•ҳм§Җл§Ң INSERT, UPDATE, DELETEл¬ём—җ м Ғмҡ©лҗЁ
- лі‘л ¬ DDL - 15к°ңмқҳ CREATE INDEX л¬ёмқ„ лҸҷмӢңм—җ мӢӨн–ү мӢңнӮӨлҠ” лҢҖмӢ Nк°ңмқҳ н”„лЎңм„ёмҠӨлҘј мӮ¬мҡ©н•ҳм—¬ лі‘л ¬лЎң лӢЁмқј мқёлҚұмҠӨлҘј мғқм„ұн•ҳлҠ” CREATE INDEXмҷҖ к°ҷмқҖ лӢӨм–‘н•ң л¬ёмқ„ лі‘л ¬лЎң мӢӨн–үмӢңнӮ¬ мҲҳ мһҲлҠ” кҙҖлҰ¬мһҗмҡ© лҠҘл Ҙ
- лі‘л ¬ DIY - мһҗкё° мҠӨмҠӨлЎң н•ҳлҠ” лі‘л ¬ мІҳлҰ¬лЎңм„ң мӢӨм ңлЎң м „нҶөм Ғмқё мҳӨлқјнҒҙ лі‘л ¬мІҳлҰ¬ кё°лІ•мқҖ м•„лӢҲлӢӨ. мҳӨлқјнҒҙмқҙ мһ‘м—…мқ„ л¶„н• н•ҳм§Җ м•Ҡкі мӮ¬мҡ©мһҗк°Җ л¶„н• н•ңлӢӨ.
лі‘л ¬ мІҳлҰ¬лҠ” ліҙм•Ҫмқҙ лҗ мҲҳ мһҲлӢӨ. нҒ° л¬ём ңлҘј м—¬лҹ¬ к°ңмқҳ ліҙлӢӨ мһ‘мқҖ л¬ём ңлЎң лӮҳлҲ„л©ҙ(л¶„н• м ‘к·јлІ•) мІҳлҰ¬ мӢңк°„мқ„ нҡҚкё°м ҒмңјлЎң мӨ„мқј мҲҳ мһҲлӢӨ. к·ёлҹ¬лӮҳ лі‘л ¬ мІҳлҰ¬лҠ” лҸ…мқҙ лҗ мҲҳлҸ„ мһҲлӢӨ. лі‘л ¬ мІҳлҰ¬лҘј л§ҺмқҖ л¶ҖлҘҳмқҳ л¬ём ңм—җ м Ғмҡ©н•ҳл©ҙ мқҙл“Өмқҳ мҶҚлҸ„лҘј м Җн•ҳмӢңнӮ¬ лҝҗл§Ң м•„лӢҲлқј м—„мІӯлӮң лҰ¬мҶҢмҠӨлҘј мҶҢ비н•ңлӢӨ.
лі‘л ¬ мҝјлҰ¬мқҳ мӢңмһ‘비мҡ©мқҖ л§Өмҡ° лҶ’кё° л•Ңл¬ём—җ лҢҖмғҒ мҝјлҰ¬к°Җ мӢӨм ңлЎңлҠ” лҠҗлҰ¬кІҢ мӢңмһ‘лҗңлӢӨ.
лі‘л ¬кҙҖлҰ¬
- лі‘л ¬кҙҖлҰ¬лҘј dbм—җ л§ЎкІЁлқј..
| create table T nologging parallel as select * from external_table |
м—¬кё°м„ң лі‘л ¬ мІҳлҰ¬мқҳ м •лҸ„лҠ” мқҙмҡ© к°ҖлҠҘн•ң лҰ¬мҶҢмҠӨм—җ к·јкұ°н•ҳм—¬ мҳӨлқјнҒҙ мһҗмІҙм—җ мқҳн•ҙ м„ нғқ лҗ мҲҳ мһҲлӢӨ.
лҢҖмҡ©лҹү лҚ°мқҙн„°м—җ лҢҖн•ң DDL мҲҳн–үмӢң Parallel мҳөм…ҳмқ„ м Ғм ҲнһҲ мӮ¬мҡ©н•ҳл©ҙ DDL мһҗмІҙмқҳ м„ұлҠҘмқ„ к·№лҢҖнҷ”н• мҲҳ мһҲлӢӨ. лҚ”л¶Ҳм–ҙ Nologging мҳөм…ҳмқ„ н•Ёк»ҳ мӮ¬мҡ©н•ҙлҸ„ мўӢлӢӨ. DDLмқҳ мҲҳн–үмҶҚлҸ„к°Җ н–ҘмғҒлҗҳл©ҙ, к·ём—җ 비лЎҖн•ҙм„ң TXлқҪ кІҪн•©м—җ мқҳн•ң лҢҖкё°мӢңк°„лҸ„ мӨ„м–ҙл“ӨкІҢ лҗңлӢӨ.
лі‘л ¬ мҝјлҰ¬
лі‘л ¬ мҝјлҰ¬лҠ” м„ұлҠҘл¬ём ңлҘј н•ҙкІ°н•ҳл©ҙм„ң мӢңлҸ„н•ҳлҠ” л§Ҳм§Җл§ү мҲҳлӢЁмқҙм§Җ кІ°мҪ” мІ« лІҲм§ё кІҪлЎңлҠ” м•„лӢҲлӢӨ.
лі‘л ¬ мҝјлҰ¬лҠ” лҸҷмӢң мӮ¬мҡ©мһҗмқҳ мҲҳк°Җ лӮ®мқҖ лҚ°мқҙн„° мӣЁм–ҙн•ҳмҡ°мҠӨм—җ мң мҡ©н•ң кё°лҠҘмқҙлӢӨ. CPUк°Җ 64к°ңмқҙкі лҸҷмӢңмӮ¬мҡ©мһҗ мҲҳк°Җ 500мқё лҚ°мқҙн„° мӣЁм–ҙн•ҳмҡ°мҠӨм—җлҠ” лі‘л ¬ мҝјлҰ¬к°Җ м Ғн•©н•ҳм§Җ м•Ҡмқ„ кІғмқҙлӢӨ. к·ёлҹ¬лӮҳ CPUк°Җ 64к°ңмқҙкі лҸҷмӢң мӮ¬мҡ©мһҗ мҲҳк°Җ 5мқё лҚ°мқҙн„° мӣЁм–ҙн•ҳмҡ°мҠӨм—җлҠ” лі‘л ¬ мҝјлҰ¬к°Җ нӣҢлҘӯн•ң мҶ”лЈЁм…ҳмқҙ лҗ мҲҳ мһҲлӢӨ.
- tomas kyteмқҳ лі‘л ¬мҝјлҰ¬м—җ лҢҖн•ң 충кі
- кҙҖл Ёлҗң н…Ңмқҙлё”мқ„ PARALLELлЎң м„Өм •н•ҳкі лі‘л ¬ мІҳлҰ¬мқҳ м •лҸ„лҘј м§Җм •н•ҳм§Җ л§Ҳлқј.
- лі‘л ¬ мһҗлҸҷ нҠңлӢқмқ„ мӮ¬мҡ©н•ҳлқј. - PARALLEL_AUTOMATIC_TUNING = TRUE(лі‘л ¬ мІҳлҰ¬м •лҸ„к°Җ мӢңмҠӨн…ң л¶Җн•ҳм—җ л”°лқј мһҗлҸҷмңјлЎң кІ°м •лҗҳкі ліҖкІҪлҗңлӢӨ)
- лі‘л ¬ мҝјлҰ¬лҘј мӮ¬мҡ©н•ҳм§Җ м•Ҡм•„лҸ„ лҗҳлҠ” л°©лҸ„лҘј м°ҫм•„лқј.
лі‘л ¬ DML
лі‘л ¬ DML(PDML)мқҖ мӢӨм ңлЎң CREATE TABLE, CREATE INDEX, лҳҗлҠ” м Ғмһ¬мҷҖ мң мӮ¬н•ң кҙҖлҰ¬ кё°лҠҘмңјлЎңм„ң м–ҙм©ҢлӢӨ л Ҳкұ°мӢң лҚ°мқҙн„°лҘј кі м№ҳкё° мң„н•ҳм—¬ н•ң лІҲм—җ лҢҖмҡ©лҹү UPDATE лҳҗлҠ” DELETEлҘј мҲҳн–үн•ҳкё° мң„н•ҳм—¬ мӮ¬мҡ©лҗңлӢӨ.
- м ңм•ҪмӮ¬н•ӯ
- мҲҳм •лҗҳкі мһҲлҠ” н…Ңмқҙлё”м—җ нҠёлҰ¬кұ°к°Җ мһҲм–ҙм„ңлҠ” м•ҲлҗңлӢӨ.
- PDMLмқҖ ліөм ңлҗ мҲҳ м—ҶлӢӨ.(мҷңлғҗн•ҳл©ҙ, мқҙмһ‘мқҖ нҠёлҰ¬кұ°лҘј нҶөн•ҙ мҲҳн–үлҗҳкё° л•Ңл¬ёмқҙлӢӨ.)
- м§Җмӣҗ к°ҖлҠҘн•ң л¬ҙкІ°м„ұ м ңм•Ҫ мЎ°кұҙмқҳ мң нҳ•м—җлҠ” м ңн•ңм ҒмқҙлӢӨ. - н…Ңмқҙлё”мқҙ лӢӨмҲҳмқҳ м„ём…ҳм—җ мқҳн•ҙ лі‘л ¬лЎң мҲҳм •лҗҳкі мһҲкі н•ң м„ём…ҳмқҙ лӢӨлҘё м„ём…ҳмқҳ ліҖкІҪ лӮҙмҡ©мқ„ ліј мҲҳ м—Ҷкё° л•Ңл¬ё
- PDMLм—җ лҚ°мқҙн„°лІ мқҙмҠӨ л§ҒнҒ¬(분мӮ° нҠёлһңг„ҙмһӯм…ҳ)мқ„ мӮ¬мҡ©н• мҲҳ м—ҶлӢӨ.
- нҒҙлҹ¬мҠӨн„° н…Ңмқҙлё”(B*нҠёлҰ¬ нҒҙлҹ¬мҠӨн„°мҷҖ н•ҙмӢң нҒҙлҹ¬мҠӨн„°)мқҖ м§Җмӣҗлҗҳм§Җ м•ҠлҠ”лӢӨ.
мң„мқҳ м ңм•ҪмӮ¬н•ӯмқ„ н•ҳлӮҳлқјлҸ„ мң„л°ҳн•ҳл©ҙ PDMLмһ‘м—…мқ„ мӢңлҸ„н•ҳл©ҙ мҳӨлҘҳ л©”мӢңм§ҖлҘј л°ӣм§ҖлҠ” м•Ҡм§Җл§Ң л¬ёмқҙ м§Ғл ¬лЎң мҲҳн–үлҗңлӢӨ. V$PX_PROCESSмҷҖ к°ҷмқҖ лҸҷм Ғ м„ұлҠҘ л·°лҘј мқҙмҡ©н•ҳл©ҙ л¬ёмқҳ лі‘л ¬ мІҳлҰ¬лҘј лӘЁлӢҲн„°л§Ғн• мҲҳ мһҲлӢӨ. |
|
[ліёл¬ёл§ҒнҒ¬] л°°м№ҳ(BATCH)нҳ• к°ңл°ң
|
|
[1]
|
|
|
|
|
|
п»ҝ
мҪ”л©ҳнҠё(мқҙкёҖмқҳ нҠёлһҷл°ұ мЈјмҶҢ:/cafe/tb_receive.php?no=31522 |
|
|
|
|
|
|
|
|
|
| |
|
|
|
п»ҝ
Copyright byCopyright в“’2005, SSISO Community All Rights Reserved.
|
|
|